Thursday, July 3, 2014
Intuition behind Geometric mean, harmomic mean (F1 value) and Arithmetric mean
http://betterexplained.com/articles/how-to-analyze-data-using-the-average/
Friday, May 2, 2014
Wednesday, March 5, 2014
Citing Accepted but Unpublished Papers in Computer Science
- Citing unpublished papers. Papers that have not yet been published do not come equipped with "official" bibliographical information, so there is some leeway in listing these papers. Depending on the nature of the work, different ways to list such papers are called for:
- Papers that have been accepted for publication, but have not yet appeared. In this case, provide the name of the journal (using standard abbreviations), followed by "to appear".
- Papers that have been submitted for publication, but have not yet been accepted. In this case, simply say "submitted", or "preprint", optionally followed by a URL if the paper is available online. There is no need to mention the journal; by not naming the journal, you can save yourself some embarrassment in case the paper ends up getting rejected.
- Papers that exist as manuscripts, but have not (yet) been submitted. Use "preprint"; if you have posted the paper on your website or on a preprint server, provide a URL.
- Papers that are "in preparation". This is a grey category and is probably best avoided. A paper listed as being "in preparation" can mean a number of things - from an idea in one's head to a rough, but complete draft. It's best to err on the conservative side and only cite items that have been written up and which physically exist.
@inproceedings{DBLP:conf/FM/yili,
author = {Yi Li and
Tian Huat Tan and
Marsha Chechik},
title = {Management of Time Requirements in Component-based Systems},
booktitle = {FM},
year = {2014. to appear.},
}
Monday, March 3, 2014
Wednesday, February 19, 2014
A Simple Algorithm for Minimal Unsatisfiable core
From here:http://www.cs.wm.edu/~idillig/cs780-02/lecture17.pdf
Ranking of Hardware Verification Conference
发现最近一直碰到hardware verification领域的人
Alan Mishchenko
Andreas Veneris/Zissis Poulos
Peh Li-Shiuan
下面是University of Toronto 的 ranking
Tier-1: DAC - ASPDAC- FMCAD - ICCAD - DATE
Tier-2: ISQED - DVCON - IOLTS
Alan Mishchenko
Andreas Veneris/Zissis Poulos
Peh Li-Shiuan
下面是University of Toronto 的 ranking
Tier-1: DAC - ASPDAC- FMCAD - ICCAD - DATE
Tier-2: ISQED - DVCON - IOLTS
Testing Terminology - Fuzz Testing
I include testing terminology that is new to me there:
Fuzz testing or fuzzing is a software testing technique, often automated or semi-automated, that involves providing invalid, unexpected, or random data to the inputs of a computer program.
Fuzz testing or fuzzing is a software testing technique, often automated or semi-automated, that involves providing invalid, unexpected, or random data to the inputs of a computer program.
Tuesday, February 18, 2014
Postdoc interview questions
Some experiences:
1. What is your 5 proudest research? and discuss them
2. When say about your research, phrase it in a way to look similar to other parties research, create the repercussion.
1. What is your 5 proudest research? and discuss them
2. When say about your research, phrase it in a way to look similar to other parties research, create the repercussion.
Monday, January 20, 2014
Security - Malware Detection
Assumption : Source code not available
Static:
n-gram
reverse engineering
Dynamic:
Machine Learning
Graph Mining
Automata (L*)
Mining Frequent Itemset
To Find:
signature (feature - system call+string value)
Direction:
Focus on
1. End-user
2. Calling sequence on internet
Static:
n-gram
reverse engineering
Dynamic:
Machine Learning
Graph Mining
Automata (L*)
Mining Frequent Itemset
To Find:
signature (feature - system call+string value)
Direction:
Focus on
1. End-user
2. Calling sequence on internet
Sunday, January 5, 2014
Hybrid concolic testing
Concolic testing could faced path exploration problem, to solve this problem, hybrid concolic testing (ICSE) method is proposed. It is mixed concolic testing with random testing, to increase the exploration to the entire "path space", rather than exploring only a region of the "path space".


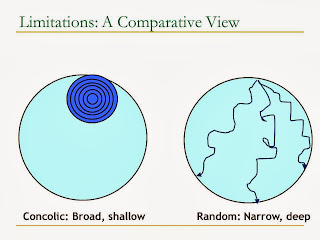






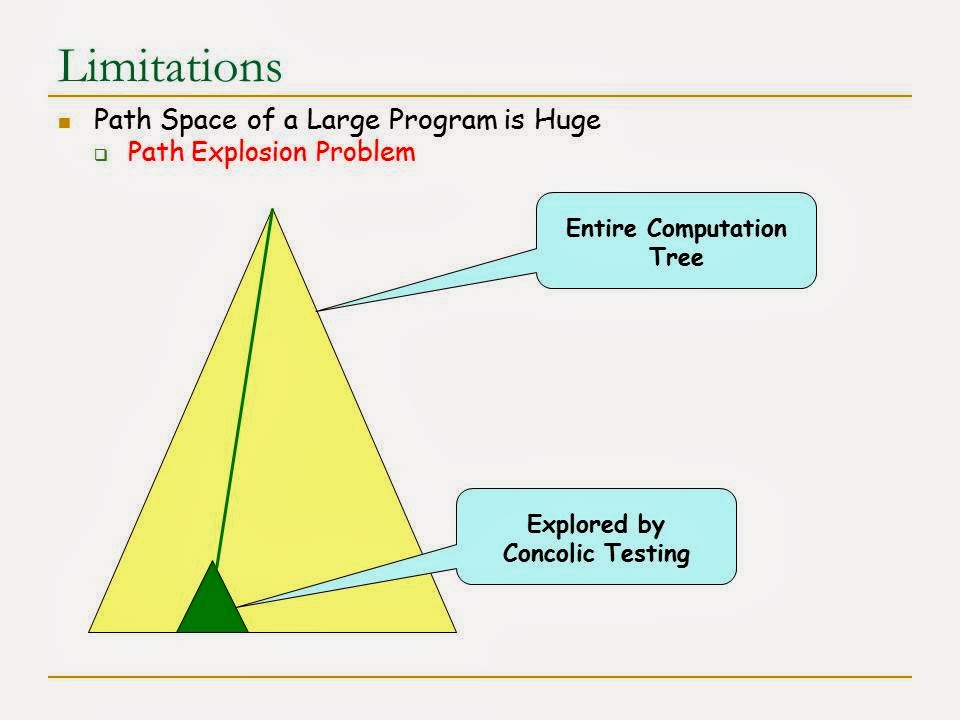






Random Testing, Symbolic Testing, Combinatorial Testing, Concolic Testing
Recently have surveyed some automated testing methods, basically it is categorized into 3 categories
 In 1997, "The Combinatorial Design Approach to Automatic Test Generation", Telcodia's studies suggest that "most field faults were caused by either incorrect single values or by an interaction of pairs of values.", so to find bug, what we could do is to find every possible pair of input, which result in the following pair. This is called pairwise testing/all pair testing/2-way testing.
In 1997, "The Combinatorial Design Approach to Automatic Test Generation", Telcodia's studies suggest that "most field faults were caused by either incorrect single values or by an interaction of pairs of values.", so to find bug, what we could do is to find every possible pair of input, which result in the following pair. This is called pairwise testing/all pair testing/2-way testing.

1. Random testing
- as its name implies, randomly generated input and test.
2. Symbolic testing
- treat the input (1,2,3) as symbolically (a,b,c), run the program symbolically, find some constraints on the input the makes the program failed. When you run to a if statement (e.g., a=b), then that branch does not failed, add a!=b to the constraint, and reexecute the symbolic execution. This continues until failures occured, and when failure occured, return the accumulated constraint to the user.
3. Combinatorial testing
- basically testing combinatory is untractable, therefore we need to make some heauristic. Some heauristic include pairwise testing, i.e., for each tuple, we only tested it once.
For example given input of three parameters
Destination (Canada, Mexico, USA); Class (Coach, Business Class); Seat Preference (Aisle, Window)
all possible testing will result in 3x3x2=18 combinations.

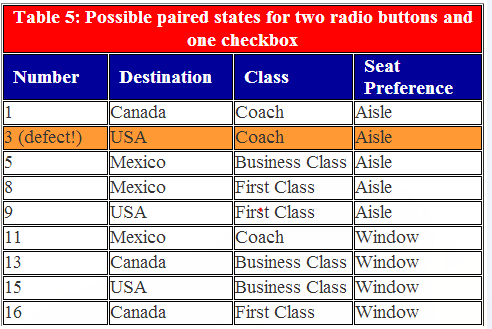
For example line 18 is removed as (USA, First Class), (USA,Windows), (First Class Windows) could be found at lines 9,15,16 respectively. This result in 9 columns (3x3=9, where we take the top 2 elements - destination, class which have 3 elements resp. - are multiplied them together).
This could be generalized to 3-way testing (or 4-way testing, etc) and so on (more thorough testing, but need more time), when the results in taking top 3 (or top 4, etc) elements multiplied together.
And some combination of these 3 categories
4. Concolic testing (concrete/random + symbolic testing)
This video gives nice introduction
http://www.youtube.com/watch?v=b8SeZTgwXEY
Problem Using random testing alone
if you generate the x randomly, then you have 1/2^32 chances to hit alone, which is not good, therefore we use symbolic execution approach, which aim to finding constraint on x using the condition, rather testing individual values on x.

Problem Using symbolic testing alone
1. For the following code symbolic testing will unable to count the value of x to execute first branch or second branch. Reason is that (x%10)*4!=17 will gives a list of infinite values of x that are disconnected, which is hard to represent using constraint. Therefore, symbolic execution told that both branches are executable, which results in false positive.

2. If we have function f(x) below, we simply can't use symbolic execution

Concolic Testing
Concolic testing keeps both concrete state and symbolic state when running.
Always use concrete states to decide the path,
The initial value of concrete states is randomly generated, subsequent values are inferred from the negation of path condition
For modulo and function - it chooses one value out of many possible values.













Problem Using random testing alone
if you generate the x randomly, then you have 1/2^32 chances to hit alone, which is not good, therefore we use symbolic execution approach, which aim to finding constraint on x using the condition, rather testing individual values on x.
Problem Using symbolic testing alone
1. For the following code symbolic testing will unable to count the value of x to execute first branch or second branch. Reason is that (x%10)*4!=17 will gives a list of infinite values of x that are disconnected, which is hard to represent using constraint. Therefore, symbolic execution told that both branches are executable, which results in false positive.
2. If we have function f(x) below, we simply can't use symbolic execution
Concolic Testing
Concolic testing keeps both concrete state and symbolic state when running.
Always use concrete states to decide the path,
The initial value of concrete states is randomly generated, subsequent values are inferred from the negation of path condition
For modulo and function - it chooses one value out of many possible values.







Here we require to negate one of the path condition to allow us explore different paths.


We hit the program errors.

It is an explicit path model checking method as it explores all the possible path in the program

This method shines when we hit the modulo and external function method, where it cannot resolve my traditional symbolic execution method

From the slide above, we use the random number 7. Noted that, this guarantee soundness, but not completeness, it allows it to pass through, but not guarantee to solve all kinds of bug.
Basically these are the methods for testing I have surveyed so far. The general observation is:
1. black box testing - (e.g., combinatorial testing, and pairwise combination is effective)
2. white box testing - coverage is important (e.g., symbolic and concolic testing)
3. random testing (used for black box testing and white box testing)
Subscribe to:
Posts (Atom)